Un sommelier de la donnée (qui extrait les arômes de vos textes)
Imaginez un instant que votre navigateur devienne intelligent. Pas juste un peu malin comme quand il devine vos mots de passe ou vous suggère une recette de gratin. Non, vraiment intelligent. Du genre capable de lire un texte de cinq kilomètres, d'en extraire l'essentiel, et de vous le servir sur un plateau, façon sommelier de la donnée.
C'est exactement ce que permet Xenova/transformers.
Derrière ce nom un peu barbare se cache une petite merveille technique : une librairie JavaScript conçue pour exécuter des modèles d'intelligence artificielle avancés dans le navigateur. Sans serveur. Sans clé API. Sans backend Python. Tout ça tourne à côté de vos mails et de votre onglet “comment faire un bon café”, sans lever le petit doigt.

Une IA qui tient dans un fichier JS
Xenova/transformers, c’est un peu le food-truck de l’IA. Il n’a pas besoin d’une usine, d’un entrepôt ni d’une autoroute de données. Il se gare discrètement et vous sert des modèles pré-entraînés tout chauds, directement depuis le Hugging Face Hub.
Traduction automatique, analyse de sentiments, génération de texte, résumé automatique… Il sait tout faire (ou presque), et surtout, il le fait localement. Avec élégance, efficacité, et confidentialité.
L’idée vient d’un développeur britannique, Ifeanyi Amadi, qui s’est demandé un jour pourquoi l’intelligence artificielle devait toujours dépendre du cloud. Résultat : une bibliothèque JS qui s’appuie sur ONNX Runtime et WebAssembly pour faire tourner de vrais modèles Transformers dans un environnement full JavaScript. Et ça tourne même dans un avion (si vous avez préchargé le modèle avant de décoller).
Une techno qui inspire la communauté
La communauté de développeurs s’est rapidement emparée de cette techno. Certains ont créé des extensions Chrome de résumé de page web en un clic, d’autres des outils de transcription audio ou de Q&A local, et même des jeux interactifs exploitant les modèles pour comprendre dessins ou mots-clés.
Transformers.js (le nom de la lib sur npm) a été pensé pour coller à l’API de Hugging Face Transformers, rendant la transition ultra fluide pour les devs habitués à Python. L’un de ses points forts ? Tout est précompilé en WebAssembly, les modèles sont téléchargeables en CDN, et le tout peut tourner dans un Worker sans bloquer l’interface.
Dans un article de blog chez Hugging Face, certains développeurs expliquent comment ils l’utilisent pour générer des résumés de documents PDF côté client, ou intégrer de la traduction automatique directement dans l’éditeur d’un CMS. Bref, une boîte à outils IA qui ne demande ni GPU ni serveur, juste un navigateur moderne.
Comment ça marche ?
Sous le capot, Xenova/transformers s'appuie sur des modèles de type "transformer" (comme T5, BERT, etc.) qui ont été convertis au format ONNX. Si vous n’avez jamais entendu parler d’ONNX, imaginez une sorte de valise diplomatique standardisée : on y range un modèle d’IA complexe, on le compacte, on le rend lisible par d’autres outils, et hop, il passe la douane du navigateur sans problème.
Ensuite, c’est WebAssembly qui prend le relais : un peu comme si on transformait ce modèle en champion de course ultra léger, capable de tourner dans n’importe quel navigateur moderne sans se prendre les pieds dans le JavaScript. Résultat : une exécution rapide, sécurisée, et surtout 100 % locale.
Quand vous initialisez un pipeline (par exemple pour faire du résumé automatique), Xenova télécharge le modèle une seule fois depuis un CDN. Il le met en cache, et à partir de là, plus besoin de connexion. C’est comme avoir un petit cerveau d’IA dans la poche de votre navigateur.
Le résumé, lui, est généré grâce à un modèle de type T5. Ce modèle a été entraîné sur des millions de paires "texte long / résumé court", ce qui lui permet de condenser l’essentiel avec un certain style narratif. Il lit, comprend, reformule — le tout, sans jamais sortir de votre machine.
Résumer un champ de base de données ? Facile.
Prenons un cas très concret : vous avez une base de données avec un champ texte type "description" ou "commentaire client". Dedans, on trouve parfois des textes courts, mais aussi des pavés de plusieurs centaines de mots.
Plutôt que de développer une API dédiée, d’héberger un modèle, ou de payer à la requête chez un provider externe, pourquoi ne pas proposer un résumé généré localement ? Grâce à Xenova/transformers, vous pouvez coller ce champ dans une zone de texte, et produire un résumé dynamique sans que la donnée ne quitte jamais l’appareil de l’utilisateur.
Et si le texte est trop long, on peut même découper le contenu en blocs (ce que fait notre POC), et résumer chaque morceau avant d’assembler le tout. Magie ? Non, juste du JS moderne et bien pensé.
Le POC : testez, copiez, adaptez
Note importante : le modèle utilisé (T5-base) n'est pas spécifiquement entraîné sur le français. Il comprend très bien la langue, mais il peut parfois glisser des mots anglais dans le résumé — des petites surprises comme "chit" ou "he effectue" peuvent apparaître. Cela reste rare, mais c’est le genre de comportement à garder en tête, surtout pour une intégration en production. Des modèles francophones existent sur Hugging Face, mais ils ne sont pas encore compatibles avec l'exécution dans le navigateur via Xenova/transformers.
Voici une petite illustration ultra simple. Une page HTML, un champ de texte, un bouton. Le modèle T5-base tourne directement dans le navigateur grâce à @xenova/transformers, et résume en quelques secondes le contenu que
vous lui donnez.
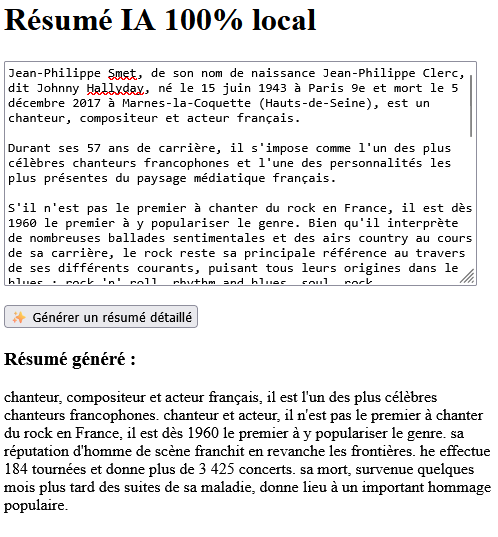
Le code source est modifiable. Réutilisable. Intégrable dans vos apps internes. Vous pouvez changer le modèle, la langue, ou même la tâche (traduction, analyse de sentiment, etc.). Le tout, sans rien installer d'autre.
ESSAYER LE POC POUR RÉSUMER UN TEXTE